深度学习框架——Darknet
视频效果展示:
通过视频的演示,我们可以了解到 Darknet 能够将图像上的物体选中并识别出来。本小节将介绍如何将开源项目深度学习框架 darknet移植到我们 handsfree ros机器人上,让我们的 handsfree ros 机器人通过摄像头完成简单的图像识别。
本文将简单的引导如何在我们的 handsfree ros机器人上使用 Darknet ,以及用下载好的模型来完成物体的识别。当然了,你还可以在机器人上基于 Darknet 来完成一些其他的开发,用于其他领域。比如对配合其他传感器和硬件设备来完成对物体进行分类、对物体的准确抓取等等、对物体的筛选等等。
关于 Darknet 框架
Darknet 介绍
Darknet 官网上是这样介绍的:
Darknet:C语言中的开源神经网络
Darknet 是一个用 C 和 CUDA 编写的开源神经网络框架。它快速,易于安装,并支持 CPU 和 GPU 计算。
引用的其他相关介绍是:
Darknet 是一个较为轻型的开源深度学习框架,由 Joseph Redmon 提出。该框架完全基于 C 与 CUDA 编写的开源神经网络框架,支持 CPU 与 GPU 两种计算方式。有一下几个特点:
- 安装和配置简单:在 makefile 里面选择自己需要的附加项(cuda,cudnn,opencv 等)直接 catkin_make 即可,几分钟完成安装。
- 没有任何依赖项:整个框架都用 C 语言进行编写,可以不依赖任何库,连 opencv 作者都编写了可以对其进行替代的函数
- 结构清晰,查看、修改源代码方便:其框架的基础文件都在src文件夹,而定义的一些检测、分类函数则在example文件夹,可根据需要直接对源代码进行查看和修改
- 易于移植:该框架部署到机器本地十分简单,且可以根据机器情况,可以选择使用 cpu 或 gpu,特别是检测识别任务的本地端部署,darknet 会显得异常方便。
什么是深度学习?
深度学习(DL, Deep Learning)是机器学习(ML, Machine Learning)领域中一个新的研究方向,它被引入机器学习使其更接近于最初的目标——人工智能
深度学习是学习样本数据的内在规律和表示层次,这些学习过程中获得的信息,对诸如文字、图像和声音等数据的解释有很大的帮助。它的最终目标是让机器能够像人一样具有分析学习能力,能够识别文字、图像和声音等数据。 深度学习是一个复杂的机器学习算法,在语音和图像识别方面取得的效果,远远超过先前相关技术。
深度学习是一类模式分析方法的统称,就具体研究内容而言,主要涉及三类方法:
- 基于卷积运算的神经网络系统,即卷积神经网络(CNN)。
- 基于多层神经元的自编码神经网络,包括自编码(Auto encoder)以及近年来受到广泛关注的稀疏编码(Sparse Coding)。
- 以多层自编码神经网络的方式进行预训练,进而结合鉴别信息进一步优化神经网络权值的深度置信网络(DBN)。
什么是神经网络?
人工神经网络(Artificial Neural Networks,简写为 ANNs)也简称为神经网络(NNs)或称作连接模型(Connection Model),它是一种模仿动物神经网络行为特征,进行分布式并行信息处理的算法数学模型。这种网络依靠系统的复杂程度,通过调整内部大量节点之间相互连接的关系,从而达到处理信息的目的。
深度学习和神经网络的关系?
神经网络简单说就是机器学习众多算法中的一类,设计的时候就是模仿人脑的处理方式,希望其可以按人类大脑的逻辑运行。
深度学习其实算是神经网络的延伸,和神经网络一样,深度学习也是一个算法的集合,只不过这里的算法都是基于多层神经网络的新的算法。
所以现在深度学习就是新的神经网络,其本质仍然是神经网络,但是又区别于旧的神经网络。另外现在基本很少在讨论神经网络了。
关于 YOLO 和 Darknet
提到 Darknet 必不可少的会提到 YOLO ,那么二者又是什么关系呢?
YOLO(You Only Look Once)是目标检测领域比较优秀的网络模型。是开发 Darkent 的作者为 Darknet 设计的配套网络模型。
Darknet是个轻量级深度学习训练框架,可以用来训练或推理。
YOLO系列是目标检测领域比较优秀的网络模型,可以用来在图像中找到若干对象,并指出对象在图中的具体位置。
另外可以在 Darknet 训练各种其他的网络模型,也可以用其他深度学习框架来训练 YOLO 网络模型。感兴趣的可以上网查阅,拓展。
关于 darknet_ros
darknet_ros 是作者 Marko Bjelonic 将 YOLO 和 Darknet 写成了一个 ros 包,可以直接在 ros 的环境下使用。
关于 darknet_ros 的话题
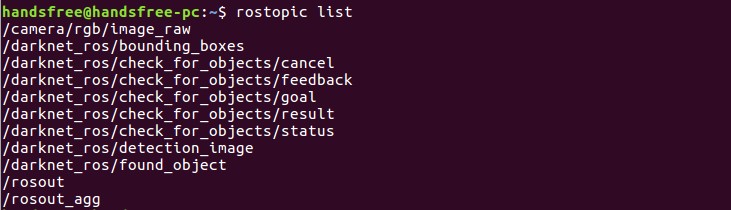
用于订阅的话题
/camera/rgb/image_raw(用于订阅摄像头获取的图像数据)
用于发布的话题
/darknet_ros/bounding_boxes(用于发布边界框数组,以像素坐标的形式提供边界框的位置和大小的信息。)
/darknet_ros/detection_image (发布包含边界框的检测图像的图像。)
/darknet_ros/found_object(检测到物体个数)
更多的了解请前往这里
准备开始
- ubuntu 版本:Ubuntu18.04
- ros 版本:ROS melodic
- 安装依赖的软件:OpenCV (computer vision library)
- 安装依赖的 C++ 库:boost (c++ library)
- 如果你是我们 handsfree 机器人的使用者,不用在单独的去安装 OpenCV 和 boost 库,我们已经安装好了。
- 这里以 Xtion 系列的深度摄像头 Xtion Pro 为例。
可以通过图片来测试一下
编译 darknet ,并将之前下载好的 yolov3 模型文件复制到 wp_date 文件下
cd ~/handsfree/darknet_ros_ws/src/darknet_ros/darknet make cp ~/handsfree/darknet_ros_ws/src/darknet_ros/darknet_ros/yolo_network_config/weights/yolov3.weights ~/handsfree/darknet_ros_ws/src/darknet_ros/darknet/wp_data/编译完成后,在 darknet 目录下使用该命令
cd ~/handsfree/darknet_ros_ws/src/darknet_ros/darknet ./darknet detect cfg/yolov3.cfg wp_data/yolov3.weights data/dog.jpg
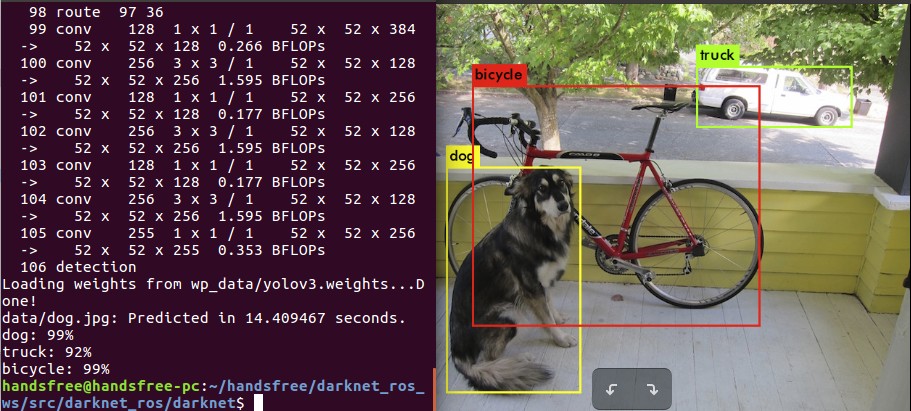
也可以用 data 目录下的其他图片或者自己通过其他途径获取的图片来测试
使用 darknet_ros_ws 功能包
打开摄像头驱动
roslaunch handsfree_camera xtion.launch使用 yolo_v3 模型文件来识别物体
roslaunch darknet_ros yolo_v3.launch可以看见打开了一个 image_view 窗口,会看到已经识别到物品,并且都识别正确了

终端会显示识别到的物品信息,以及一个百分比,这个百分比是机器对于图中对象准确率的判断。

到了这里我们已经完成了深度学习框架 darknet 的安装和简单使用。但是你会发现,显示器显示的图像数据会很慢,延迟很高,实时效果差。虽然能识别物体,但是卡顿感很明显。出现如此不好的体验,我们当然有对应的解决方案。
前面的介绍有提到 darknet 是支持 cpu 和 gpu 计算的。而这里我们使用的是用 cpu 来运行 Darknet 和 YOLO v3。cup 和 gpu 的计算速度相差很大,有几百倍的差距。(这里的 gpu 指的是英伟达支持CUDA的 gpu)
那么需要如何使用 gpu 呢? 我们先查看一下 Makefile 文件。
相关拓展
认识 GPU
图形处理器(英语:Graphics Processing Unit,缩写:GPU),又称显示核心、视觉处理器、显示芯片,是一种专门在个人电脑、工作站、游戏机和一些移动设备(如平板电脑、智能手机等)上做图像和图形相关运算工作的微处理器。GPU 使显卡减少了对 CPU 的依赖,并进行部分原本 CPU 的工作,尤其是在 3D 图形处理时 GPU 所采用的核心技术有硬件 T&L(几何转换和光照处理)、立方环境材质贴图和顶点混合、纹理压缩和凹凸映射贴图、双重纹理四像素256位渲染引擎等,而硬件 T&L 技术可以说是 GPU 的标志。
认识 CUDA
CUDA (ComputeUnified Device Architecture),是显卡厂商NVIDIA推出的运算平台。 CUDA是一种由NVIDIA推出的通用并行计算架构,该架构使GPU能够解决复杂的计算问题。
认识 CUDNN
NVIDIA cuDNN是用于深度神经网络的GPU加速库。它强调性能、易用性和低内存开销。NVIDIA cuDNN可以集成到更高级别的机器学习框架中,如谷歌的Tensorflow、加州大学伯克利分校的流行caffe软件。简单的插入式设计可以让开发人员专注于设计和实现神经网络模型,而不是简单调整性能,同时还可以在GPU上实现高性能现代并行计算。
认识 OPENCV
OpenCV是一个开源发行的跨平台计算机视觉和机器学习软件库,可以运行在Linux、Windows、Android和Mac OS操作系统上。 它轻量级而且高效——由一系列 C 函数和少量 C++ 类构成,同时提供了Python、Ruby、MATLAB等语言的接口,实现了图像处理和计算机视觉方面的很多通用算法。
认识 OPENMAP
OpenMP提供的这种对于并行描述的高层抽象降低了并行编程的难度和复杂度,这样程序员可以把更多的精力投入到并行算法本身,而非其具体实现细节。对基于数据分集的多线程程序设计,OpenMP是一个很好的选择。同时,使用OpenMP也提供了更强的灵活性,可以较容易的适应不同的并行系统配置。线程粒度和负载平衡等是传统多线程程序设计中的难题,但在OpenMP中,OpenMP库从程序员手中接管了部分这两方面的工作